Pipelining HTTP
|
|
Aidez à ajouter des liens dans les articles relatifs au sujet.
|
Le pipelining HTTP est une technique consistant à combiner plusieurs requêtes HTTP dans une seule connexion TCP sans attendre les réponses correspondant à chaque requête.
Le pipelining présente plusieurs avantages:
- amélioration importante du temps de chargement des pages, en particulier sur des liaisons présentant une forte latence
- réduction de la charge pour l'infrastructure réseau ainsi que pour les serveurs et clients HTTP
Le pipelining nécessite, de la part du client aussi bien que du serveur, le support de la norme HTTP 1.1 telle que décrite dans la RFC 2616.
Sommaire |
[modifier] Principe
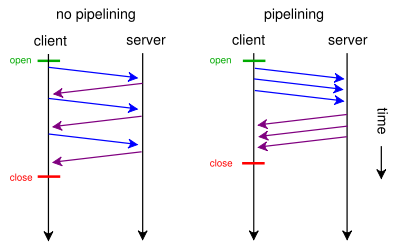
Dans la version 1.0 du protocole HTTP, le traitement des requêtes est séquentiel. Le client doit effectuer une nouvelle connexion TCP avec le serveur pour chaque objet (page, image, etc.) demandé et attendre le résultat avant de pouvoir poursuivre avec la requête suivante.
La technique du pipelining contourne ce problème en exploitant le principe de connexion persistante (keepalive). Lorsque le client envoie une requête HTTP au serveur, celui-ci inclut dans sa réponse la version du protocole HTTP utilisée. Si les deux extrémités utilisent HTTP 1.1, la connexion sera par défaut persistante. Le client doit indiquer qu'il souhaite fermer la connexion persistante avec le message "Connection: close" lorsqu'il ne souhaite plus utiliser la connexion.
Le pipelining peut alors prendre place sans autre négociation. Il consiste à envoyer plusieurs requêtes à la suite sans attendre leurs résultats. Le serveur HTTP a l'obligation de renvoyer les réponses exactement dans le même ordre que les requêtes.
On remarquera que puisqu'il est nécessaire qu'il y ait un échange complet entre client et serveur pour s'assurer qu'ils supportent bien tous les deux HTTP 1.1, les requêtes constituant une nouvelle connexion ne peuvent pas être l'objet du pipelining. De même, seules les requêtes idempotentes[1] — telles que GET, HEAD, PUT et DELETE — peuvent faire l'objet du pipelining.
[modifier] Avantages
L'utilisation du pipelining hérite plusieurs avantages de l'utilisation des connexions persistantes. Ces avantages sont résumés dans la section 8.1.1 de la RFC 2616 décrivant le protocole HTTP 1.1. Notamment:
- En ouvrant et fermant moins de connexions TCP, routeurs et hôtes (client, serveur, serveur mandataire, etc.) économisent du temps CPU. Les hôtes en particulier économisent la mémoire utilisée pour les blocs de contrôle TCP.
- La congestion du réseau est diminuée par la réduction du nombre de paquets dus à l'ouverture de la connexion TCP, et par le fait qu'on laisse suffisamment de temps à TCP pour déterminer l'état de congestion du réseau.
- La latence est réduite pour les requêtes suivantes puisqu'on ne perd pas de temps à cause de l'initialisation de la connexion TCP. De plus, en début de connexion, l'algorithme Slow Start implique un débit plus réduit que pour une connexion établie.
L'avantage supplémentaire à l'utilisation du pipelining est qu'un client peut effectuer plusieurs requêtes sans attendre chaque réponse, permettant à une seule connexion TCP d'être utilisée avec plus d'efficacité, dans un temps plus court. Le concept est similaire aux mécanismes de fenêtre glissante dans TCP ou fenêtre d'anticipation dans HDLC.
[modifier] Problèmes
Le W3C a conduit en 1997 une étude sur les performances obtenues grâce aux nouveaux standards de l'époque qu'étaient HTTP 1.1, CSS1 et PNG. L'application construite à l'occasion de ces tests utilisait le pipelining. Les résultats ont montré que HTTP 1.1 avec connexions persistantes et pipelining réduisait d'un facteur 6 le nombre de paquets envoyés mais introduisait une latence supplémentaire d'un facteur 1.5 à la grande surprise des auteurs. HTTP 1.1 est dans tous les cas plus rapide avec pipelining que sans.
Les auteurs de l'étude ont conclu à une possible interférence entre le pipelining et l'algorithme de Nagle mis en œuvre par TCP. Celui-ci effectue en effet, au niveau 4 du modèle OSI, le même type de mise en tampon des données que le pipelining au niveau 7. Cette succession de mise en tampon introduit un délai supplémentaire à l'envoi des données. C'est pourquoi il est recommandé pour les clients et les serveurs utilisant HTTP 1.1 avec pipelining de désactiver purement et simplement l'algorithme de Nagle, ce qui est habituellement possible dans l'interface BSD socket via l'option TCP_NODELAY.
Ce problème avait également été identifié en 1997 par John Heidemann dans une étude portant sur les connexions persistantes dans HTTP. Il l'avait alors appelé "Short-Signal-Segment Problem". Plusieurs autres problèmes provenant d'interaction entre TCP et HTTP 1.1 sont abordés dans son étude mais concernent les connexions persistantes et pas seulement le pipelining.
Par ailleurs, le pipelining perd son intérêt lorsqu'une requête est bloquante et nécessite d'attendre son résultat pour pouvoir procéder à l'envoi de requêtes HTTP subséquentes. En cas d'échec on doit alors retenter la requête. Aucune ressource n'est donc économisée au niveau de TCP. Un tel cas de figure se produit par exemple lorsqu'un client reçoit des réponses 401 ou 407 ou même des redirections 3xx (voir Liste des codes HTTP) en réponse à une HTTP Authentification.
[modifier] Pipelining et serveurs mandataires
La RFC 2616 indique que lorsqu'une connexion fait l'objet de pipelining, les réponses doivent être envoyées dans le même ordre que les requêtes. Lorsqu'un serveur mandataire se trouve entre le serveur et le client, il doit donc en faire autant. Or un client peut accéder à plusieurs serveurs simultanément à travers le serveur mandataire, imposant à celui-ci de conserver en mémoire l'ordre des requêtes pour chaque paire client/serveur.
Cette opération s'avère rapidement complexe lorsqu'on augmente le nombre de clients et implique de temporiser les réponses pour pallier les problèmes de déséquencement qui peuvent apparaître dans un réseau TCP/IP[2]. Les difficultés augmentent encore lorsqu'on tente de profiter du serveur mandataire pour répartir la charge sur plusieurs serveurs web.
[modifier] Implémentations
La norme HTTP 1.1 impose de supporter le pipelining sans pour autant rendre son usage obligatoire. Ce sont les clients qui prennent la décision d'utiliser le pipelining si le serveur le supporte.
- Clients :
- Mozilla Firefox 2.0 et 3.0 supportent le pipelining mais le désactivent par défaut.[3]
- Opera supporte le pipelining depuis la version 4.0 et l'active par défaut.[4]
- Internet Explorer 8 supporte le pipelining, jusqu'à 6 requêtes simultanées.[5]
- Serveurs :
- Apache supporte le pipelining depuis (au moins) la version 1.3.
- IIS supporte le pipelining depuis la version 4.0.[6] Ce support étant défectueux, il a été supprimé dans les versions suivantes[réf. nécessaire].
- Serveurs mandataires
La plupart des serveurs mandataires sont capables de servir un client qui fait du pipelining. Cependant, ils ne sont pas capables d'envoyer des requêtes pipelinées vers le serveur en amont.
La seule exception connue est Polipo, qui utilise le pipelining de façon agressive. Voir The Polipo Manual: 1.4.2 Pipelining.
[modifier] Références
- (en) RFC 2616 définissant HTTP/1.1 (lien direct vers le pipelining)
- (en) Performance Interactions Between P-HTTP and TCP Implementations (Interactions entre connexions HTTP persistantes et TCP)
- (en) Network Performance Effects of HTTP/1.1, CSS1, and PNG (étude de l'impact de HTTP/1.1 sur les performances réseaux)
- (en) HTTP/1.1 Pipelining FAQ
- (en) Key differences between HTTP/1.0 and HTTP/1.1
- (en) "Optimizing Page Load Times" article (Optimiser le temps de chargement d'une page)
[modifier] Notes
- ↑ (en) Voir RFC 2616, section 9.1.2, Idempotent Methods
- ↑ (fr) Gestion d'une connexion HTTP avec pipelining dans un proxy
- ↑ (en) Voir Firefox Help: Tips & Tricks, Enable pipelining.
- ↑ (en) Voir Opera 4.0 Upgrades File Exchange: Includes HTTP 1.1.
- ↑ (en) Voir Expertzone chat.
- ↑ (en) Voir Microsoft Internet Information Server Ressource Kit, Chapter 1.